
How a Vehicle Learns to Intercept Targets and Avoid Obstacles by Itself
We are interested in the problem of automated skill learning. In particular we focus on tasks that can be carried out with human-like rule based logic such as driving a car, or playing a game so that we can follow the learning progress. We know, for example, "if the target is on the left then turn left" is a useful rule. Of course, such a rule can be written down for a vehicle to use in a fuzzy logic control system. It is more interesting, however, to have vehicle that figures out this rule "on its own", without us telling it what to do. If we are successful at developing such a skill learning capability, then the vehicle can learn what it needs to know to handle a particular situation that an human expert himself or herself has not even thought of. We explore the use of fuzzy logic and genetic algorithm to accomplish this goal. In this experiment, the robot is given a "dictionary" consisting such terms as fast, slow, turn left, turn right, speed up, slow down, target, at least, some, don't care, etc... Its job is to assemble these terms to produce if-then rules that it will then execute in an environment where the placement of the (possibly moving) target and obstacles is continuously changing. Depending on how well it can intercept targets or avoid obstacles, it will be given a score. Vehicles with higher scores will be allowed to survive and "reproduce", and others discarded. If we think of target as food, then the environment itself will determine which vehicles can survive, and we don't need to play God. Reproduction involves exchange of rules, in whole or in part, to produce a new generation vehicles with a new generation of rule bases. We can either think of this as evolution of a population of vehicles, each with its own rule base, or the evolution of a single vehicle that has an evolving set of rule bases in its memory. The two cases are the same algorithmically. What is fun about this project is that at the end of the learning process, we can look at the rules that it has learned "on its own", and to see if they make sense to us humans. This work will be reported in Griffith and Phan (to appear).
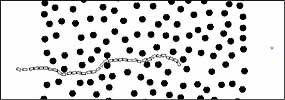
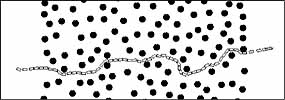
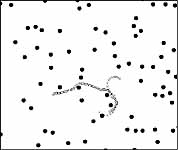
Illustration: The following figures show typical behavior in the vehicle ability to (1) intercept a stationary target, (2) intercept a moving target, (3) intercept a stationary target across an obstacle field, and (4) intercept a moving target in a obstacle field. The rules it learned do make human sense, except for one (the last rule in table) that took some effort to explain. By close monitoring of the vehicle behavior, we learned that the effect of this rule was to start a chain of actions that made the vehicle either left-handed or right-handed. Because it did not have these terms in its dictionary, it "learned" to create the same effect using only the available terms.






| If
vehicle speed is slow and the target is close and straight ahead
then speed up. If the target is on the left then turn left. If the target is far and straight ahead then speed up and go straight. If vehicle speed is medium and the target is very close then brake and go straight. If vehicle speed is fast and the target is close then brake. If the target is on the right then turn right. If vehicle speed is fast and at least one obstacle is very close and to the left then keep speed and turn right. If vehicle speed is fast and at least one obstacle is straight ahead then brake. If vehicle speed is fast and at least one obstacle is very close and to the right then speed up and turn left. If vehicle speed is medium and all obstacles are far and straight ahead then speed up. If at least one obstacle is far and to the right then obstacle avoidance has high priority. |